Yolo v3 and v5
YOLO v3 and v5
yolov3
- Single shot detector i.e the object detection (classificatio + localization/regression) happens within a single network
- fully convolutional layers - no fully connected layer
- no max pooling - convolution with stride 2 and residual connections to prevent from gradient problems
- uses FPN - feature pyramid network by upsampling the feature map(s) in the later part of the network after the bottleneck/middle layer and concatenating them with the previous layers of respective dimensions
- the FPN enables the detection of the objects at different scales/dimensions i.e why we can have detection heads for 13x13, 26x26 grid sizes and so-on
- FPN enables this by incorporating semantic information from last layers with the fine grained information from the early layers making the detection possible at different scales
- the bounding box priors/anchors are formed from K-Means Clustering ( on the sample data probably ?)
- input dimensions: Nx416x416x3
- uses Leakly RELU as the activation functions
- grid of three sizes - different grid sizes to accomodate the detection of objects of different sizes in the : (what i implemented with keras/tf) or (Original implementation in the paper)
- 13x13 or 19x19 - bigger sizes / big object detections - as they have larger context/more semantic information sampled into low resolution feature maps
- 26x26 or 38x38
- 52x52 or 76x76 - small object detections possible - as they have high resolution feature maps coz of the dimensions and low level features (fine grained information) from the very first layers of downsampling convolution are concatenated.
- last but one layer output dimensions before the final output dimension is calculated using 1d convolution is (N, K_W, K_H, O) :
- Nx13x13x1024
- Nx26x26x512
- Nx52x52x256
- the N represents the batch and only used in training and batched inference - for single frame inference, we usually just have the tensor dimension as for example for 13x13 : 1x13x13x1024
- last detection layer (CNN Layer) dimensions kernel/weights dimensions are as follows(K_W, K_H, I, O) for the MSCOCO dataset(so the dimensions of the last layer actually depend on the number of classes in a sense):
- 1x1x1024x425
- 1x1x512x425
- 1x1x256x425
- output dimensions depend on the following:
- selected grid size from the above options
- number of classes for detection
- for example for a 13x13 grid and for MSCOCO dataset(80 classes) it is: 13x13x425
- 13x13x5(85) = 13x13x5x(5 + 80) = 13x13x5x([Pc, bx, by, bw, bh],[P0, P1, P2,…. P80])
- 13x13 is the grid dimensions (feature map dimensions)
- 5 i.e 5 bounding boxes for each grid of various aspect ratios
- 5 + 80: - 5: - is the objectness probability - offset corrected x, offset corrected y( i.e x_centre, y_centre) of the bounding box - bounding box height, bounding box width - 80: for above example 80 probabilities of different class for detection (p1,……. p80) in the MS COCO Dataset
- 13x13x5(85) = 13x13x5x(5 + 80) = 13x13x5x([Pc, bx, by, bw, bh],[P0, P1, P2,…. P80])
- so final putput dimensions will be as follows:
- Nx13x13x425
- Nx26x26x425
- Nx52x52x425
yolov5
- the yolov5 has a series of CBS(convolution, batchnorm and SiLU) and C3 layers(convolutional layers) + SPPF network + PAN network before sending that to a detection head
- SPPF - used for feature representation
- the detection head comprises of the last layer with a 1-D convolution with the
- SiLU:
- Sigmoid integrated Linear Unit
- nearly 0 for the all the -ve numbers
- its differential is dSiLU - almost resembles a sigmoid with its highest value around 1.1 and lowest value around
- the detections are done at three different scales with three different grid sizes for the last feature maps:
- Nx20x20x
- Nx40x40x
- Nx80x80x
- also yolov5 has 4 different versions each with different number of model parameters/weights, they are written down below in the descending order of their model sizes
- yolov5x - extra large -
- yolov5l - large -
- yolov5m - medium -
- yolov5s - small -
- yolov5n - nano -
DeepSORT
- Started with SORT - Simple Object Realtime Tracking
- uses Linear Kalman Filter for tracking - may fail whenever occlusions occur
- detections come from the yolov5 model
- each detection in the initial frames that cross a particular IOU and NMS threshold are selected and if the detections of that class are persisted across the first three frames - a track is initiated for them with a high variance on the velocity
- after a track is initiated for the detected object - the linear kalman filter is then used to propagate that detection for the next frame and once a new detection of the same class occurs in the next frame - the prediction is associated with new detection and its track is corrected (basically the position and velocity)
- the association or matching is generally done using the IOU thresholding between the detected bounding box (coming from yolov5) and predicted bounding box (coming from the linear Kalman filter).
- if the IOU is less than the IOU threshold - then a new track is created for that detection
- any track without an association with a detection for 2 frames consecutively are deleted
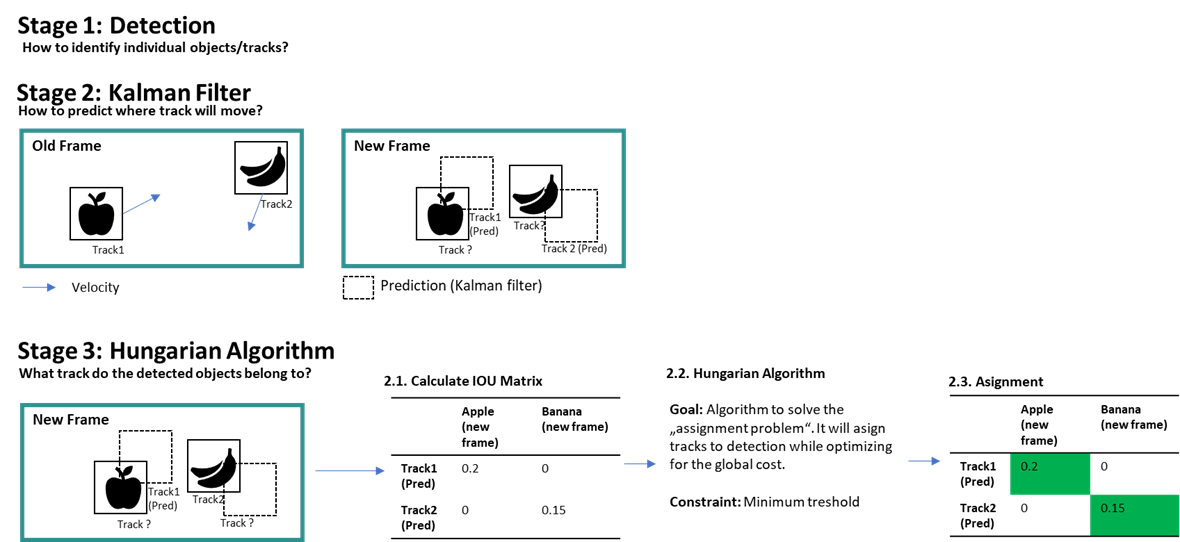
- DeepSORT: continuation of the SORT method. Deep comes from the Deep feature appreance descriptor that is used for detection to track association done by Hungarian Algorithm
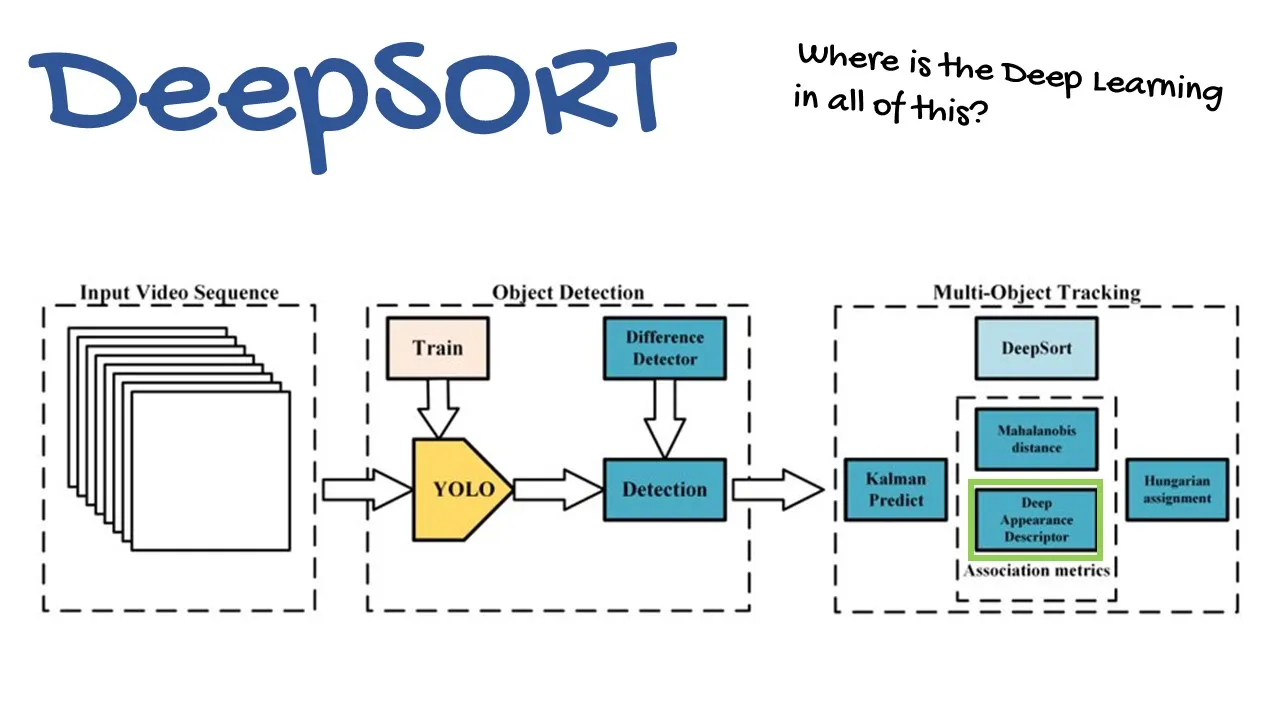
- has four things:
- Track handling and state estimation with kalman filter
- Assignment
- Matching Cascade
- Deep Appreance descriptor
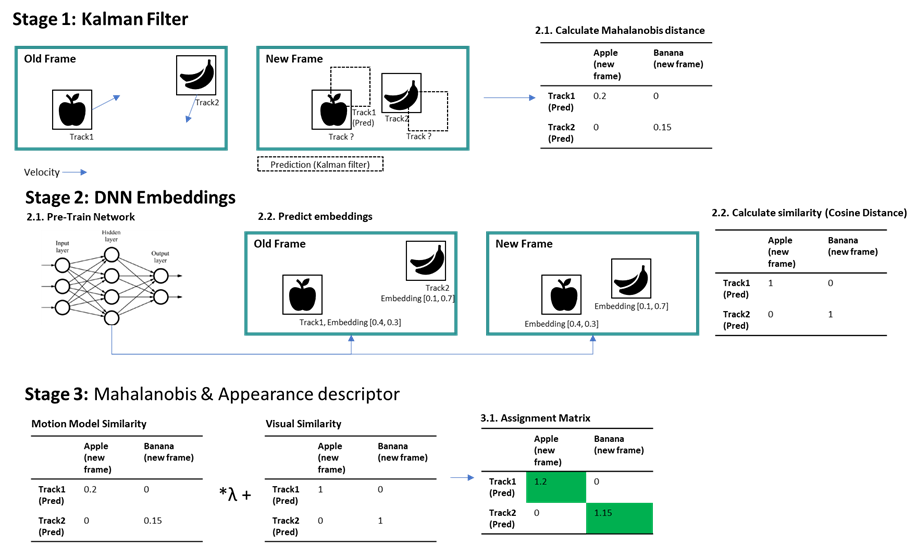
- Deep appearance descriptor - another encoder that is present that is trained with the detections/objects - where the last Fully connected layer of a CNN is taken out - giving us the feature map that represents the detections/objects
- DeepSORT then establishes an appreance based nearest neighborhood function to match the measurement to tracks calling it - Measurement to Track Associtation (MTA) - it is basically a combination of cosine similarity between the appearance of the detections and the tracks + mahanolobis distance between the detection bounding boxes and the track predicted boxes
- Assignment is done with the detection that has the least or the smallest cosine distance between the appearance feature vectors
- The number of frames threshold (Max_frames) = 30 for a track to persist without any associations with detections after which the tracks are deleted, if the object reappears in the scene after this - it is given a new ID
- sometimes this is caused by the object actually leaving and re-entering the scene but most of the times, this can also occur because the object is occluded for a very long duration
- this is the case when ID switching occurs
- this can only induce other effect where we have mixed tracks with different number of frames from the last assignment
- sometimes
Matching Cascadehelps in preventing the ID switches as it greedily makes the assignment of the detection with the track that has the least number of frames since the last assignment 
- some of the implementations go as fast as 50 fps
- some of the other altrentiaves to DeepSORT are Tracker++.. but are generally slower and cannot deal with occlusions greatly.
- Important Metrics that are considered during tracking:
- MOTA - Mullti object tracking accuracy
- MOTP - Multi object trackung precision
- IDF1 - f1 score for each id in the multiple objects
References:
This post is licensed under CC BY 4.0 by the author.