System Design Basics
system design basics in a hurry
basicworking of mobile or web application service
any basic mobile or web application needs three things at minimum:
- server
- user with the application
- dns(domain naming service)
then for further scaling it to 50 to 100 users and growing, we add a database (one good usecase for database is to store user data)
web tier
- webtier servers are used for serving the websites or applications
- to address huge traffic and scale them
- we either scale up - vertical scaling - involves increasing the compute, CPU, memory and storage of the server
- scale out - horizontal scaling - involves adding more servers and providing a load balanceer
- typically scale out is preffered to scale up
- more availability
- can avoid SPOF(single point of failure)
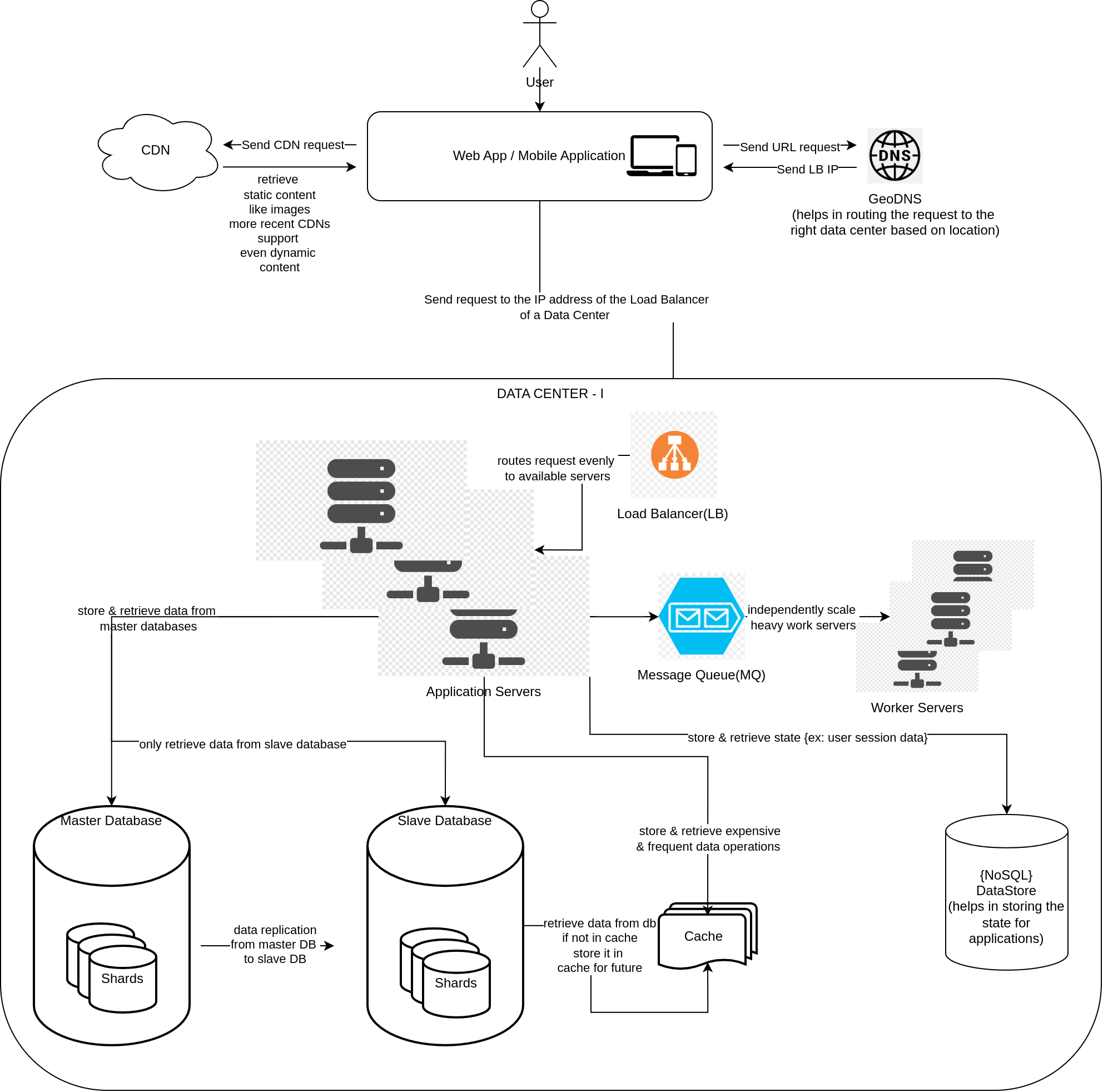
- typical diagram looks like this with a load balancer - load balancer is uses to route the requests from a users application client to one of the server within a network cluster - in this mode, the private IP addresses of the server are known to the load balancer and are not exposed to the externsl internet and the users /user’s client actually receives the public IP of the load balancer
- the name load balancer - also tells that it balances load across all the servers by routing the requests to the server evenly.
data tier
- essentially databases: persistent data storage
- two types:
- relational databases(RDMS)
- tabular rows and columns
- typically sql databases like PostgresQL
- RDMS serve purpose for most of the applications - it is totally okay to consider them first
- non-relational databases
- key-value stores are one of the most implemented type
- NoSQL database is a typical example
- used when we want to have less latency and most of the work needed would be to just serialize and deserialize the data{JSON, XML, YAML etc}
- relational databases(RDMS)
- sometimes the data gets too big in size within a database, so we divide the data into smaller chunks called shards
- sharding is done typically using hashing - with a hash function
- one example hash function for sharding user’s data can be: user_{id}%shards, so that it evenly distributes all the user data equally into all the available shards
- has some problems when the hashing function unequally distributes the data - so picking the right sharding key ( in the above case - user_{id}) becomes important
- celebrities - we should not make the mistake of sharding all the celebrity accounts into one shard - as they will have a lot of data queries (as they will have many followers)
- Consistent hashing is a technique that is used to shard and avoid some of the problems that are listed above
caches
- for fast retrieval on frequent and expensive data queries
- not a persistent data storage - hence the memory wipes out if it is restarted
- has an expiration policy on all the data it stores, as storing the data too or too short can cause:
- too long - the data becomes stale and the new data needs to be added and we will have to manually delete the data
- too short - can create cache-miss and then need to query data from database defeating the purpose of the cache
- has eviction policy on the data based on use cases, generally the following are used:
- LRU - least recently used - the data that’s not being used or queried from some time
- LFU - least frequently used - the data with the least number of queries
- FIFO - first in first out
- also sometimes more than one cache is used to avoid SPOF(single point of failure)
- caches are also over-provisioned sometimes to handle the traffic accordingly if the other caches become unavailable due to some reasons
- typical examples is Redis
datastores
- datastores are (generally)NoSQL databases that allow to store the state of an application served with the webtier-server
- NoSQL for faster retrievals (typically these can contain user session data)
stateful web-tier servers
- servers that preserve the state of the application (for example: a user’s session data)
- can be done using sticky sessions such that requests corresponding to a particular are sent to the same server where their existing session is present
- but this is not a scalable approach
- example:
- three users : A, B, C each working with three stateful servers A, B, C respectively where their session data is persisted
- there will be a overhead at the load-balancer to fgure out the exact server for each request for that specific user
- and if the server A is offline for some reason, the user A will no longer be able to use the application
stateless web-tier servers
- this architecture generally scales well as it mitigates most of the issues described above and basically has a datastore {usually a NoSQL database} storing the state (ex: user session data)
data-centers
- applications are scaled for more than 10,000 to 1M users using data-centers from multiple regions
- geoDNS makes a geo-location based routing of the traffic possible i.e users belonging to a particular
- so this handles a single point of failure in cases where a data-center is offline
- data-center level replication of data is required - sometimes the data is inconsistent across the databases of different data-centers
- to maintain the consistency of the data across the data centers sis quite difficult
message queues
- for further scaling, webtier servers can further be made independent from worker servers heavylifting the work like heavy data, image or video processing etc
- message queues support the scalability with there publish, subscribe architecture
- webtier servers can publish some processing requests as jobs to worker servers and these can be consumed (subscribed) by the workers servers
- once processed, the results are published by the worker servers to the webtier application servers
- the message queues help in as the producers need not be available after sending the requests and can come back online whenver they are receiving the results back abd vice versa with the worker servers
other important things
- logging errors and monitoring becomes more of a necessity than a good practice as we scale the application to > 1000 users depending on the use-case
- metrics:
- application metrics: like for prediction services: accuracy - etc
- setup metrics : throughput, latency of the servers etc
- business metrics
references
this material is my understanding of Alex Xu’s System Design
This post is licensed under CC BY 4.0 by the author.