Ray Data Shuffling
Ray data shuffling
Shuffling or randomizing the order of the data becomes important for ML workloads specifically for Training. I have tried to visualize some of the data shuffling approaches that Ray offers through these diagrams. This blog and diagrams assume some familiarity with Ray Data.
file shuffle
- shuffles the order of input files loaded to the worker before reading
- less compute and time intensive
- might not be sufficient as the rows within the files still maintain the same order, so if file sizes are big - not at all an effective shuffling mechanism
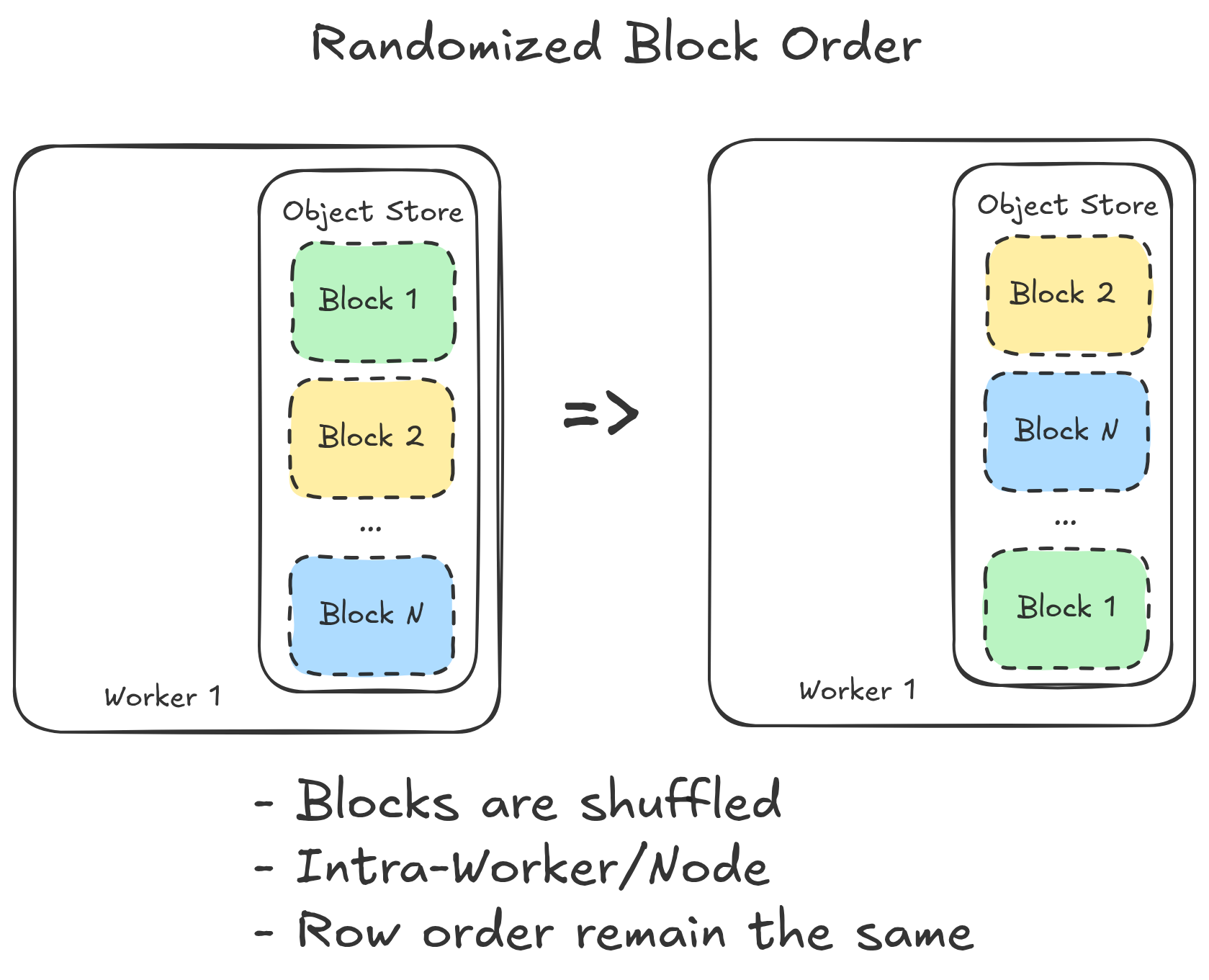
randomizing block order
- the next one on the list offers shuffling across blocks of a dataset(Ray.Dataset) by randomizing their order
- first materializes all the blocks into the distributed plasma object store
- the head node with the list of the Object Refs then randomizes the order within the list (no actual data movement)
- downstream operators for training can then call these objects in the randomized order for training
local shuffling and local shuffle buffer
ray offers intra-node row shuffling:
- can be achieved with iteration methods such as the
iter_batches()oriter_torch_batches()oriter_tf_batches() - can be combined with file level shuffling
- an important hyperparameter that might affect the time spent on batch creation from the dataset
local_shuffle_buffer_size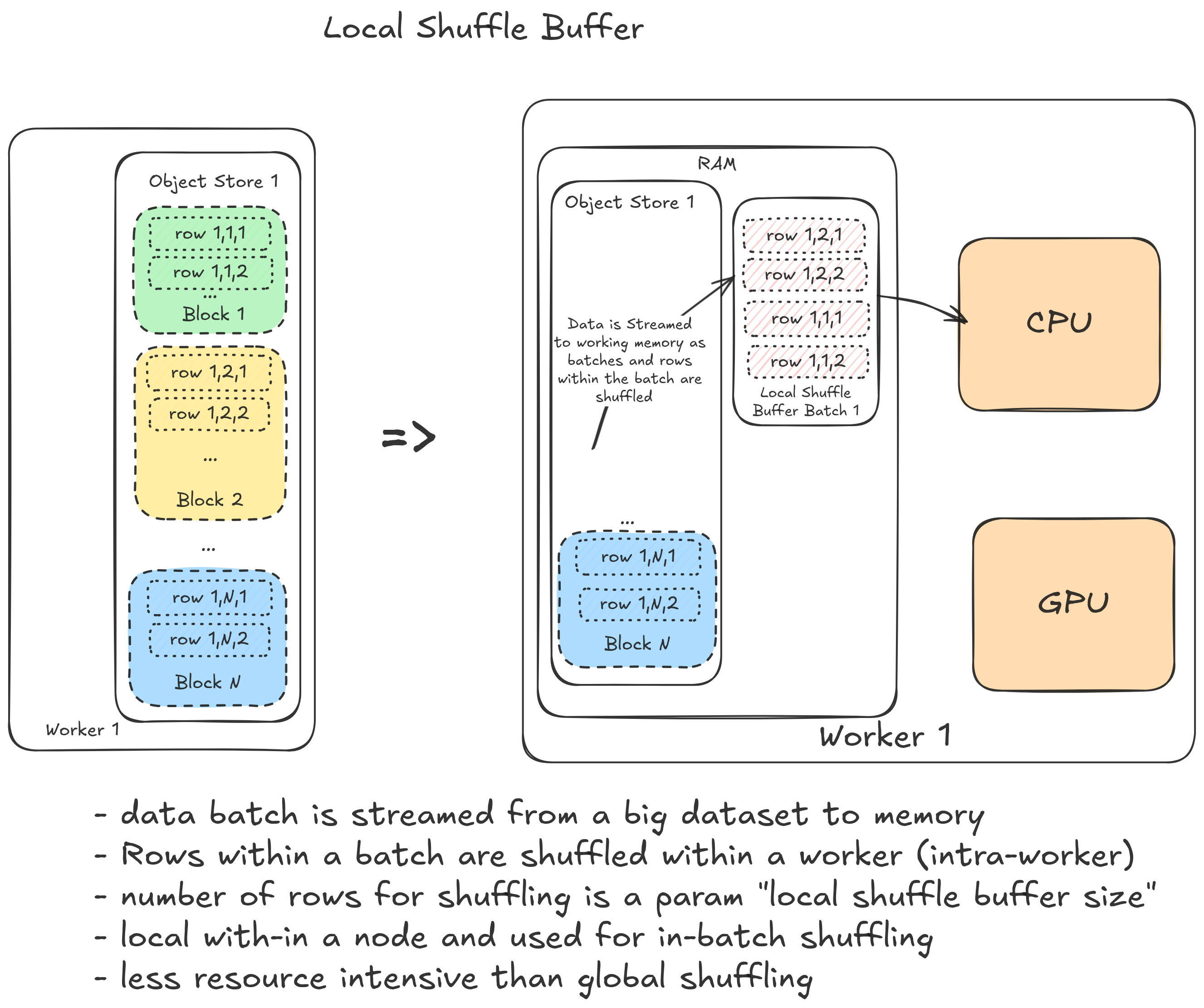
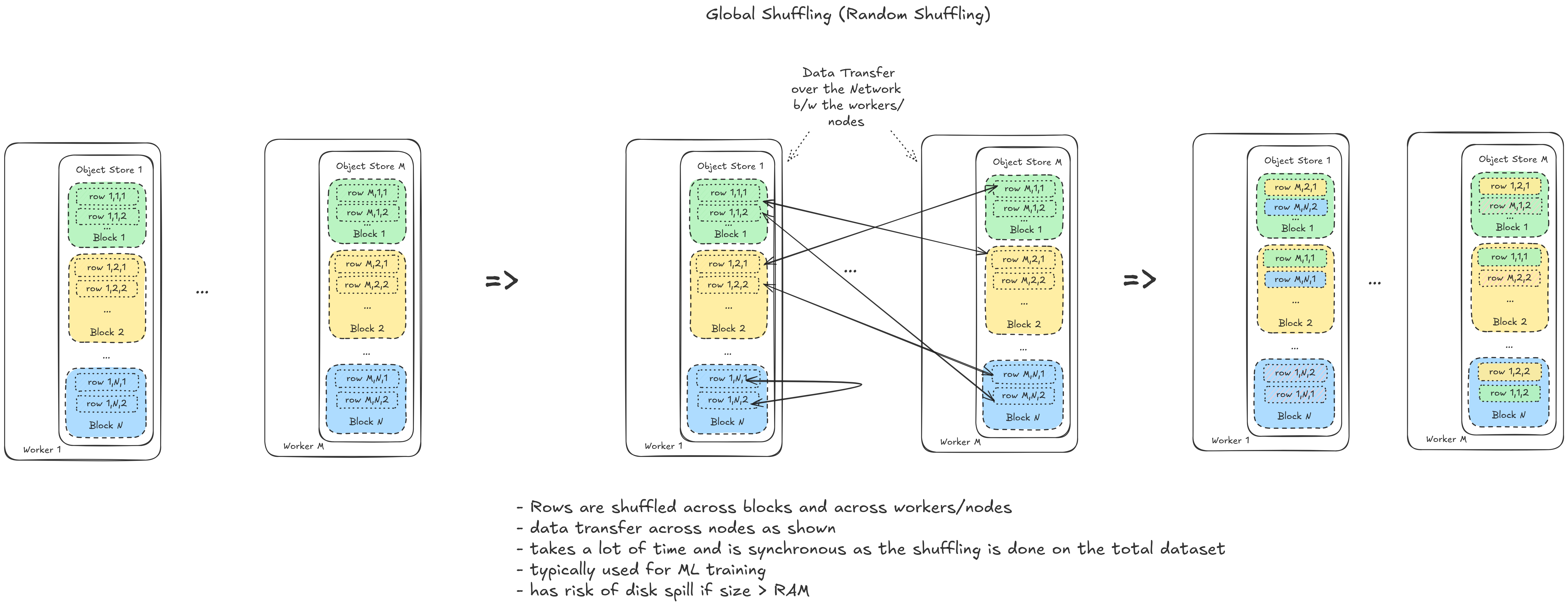
global shuffling

upcoming:
diagrams on the following:
- push based shuffling
- detailed operations, data flow for all the data shuffling methods
This post is licensed under CC BY 4.0 by the author.